

Xu Rui — Clustering, краткое содержание
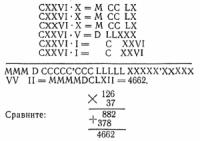
This is the first book to take a truly comprehensive look at clustering. It begins with an introduction to cluster analysis and goes on to explore: proximity measures; hierarchical clustering; partition clustering; neural network-based clustering; kernel-based clustering; sequential data clustering; large-scale data clustering; data visualization and high-dimensional data clustering; and cluster validation. The authors assume no previous background in clustering and their generous inclusion of examples and references help make the subject matter comprehensible for readers of varying levels and backgrounds.
Чтобы оставить свою оценку, войдите или зарегистрируйтесь





📖 О книге «Clustering»
На Книгизм представлено произведение «Clustering» — книга автора Xu Rui. Книга относится к жанру «Математика» . Полный текст доступен бесплатно — для чтения онлайн в браузере или скачивания в формате fb2.
🏷️ Жанры книги
Произведение «Clustering» относится к следующим жанровым направлениям каталога Книгизм:
👥 Похожие авторы в жанре
Если вам понравилась эта книга, обратите внимание на других популярных авторов в жанре «Математика»:
❓ Часто задаваемые вопросы
Можно ли скачать книгу «Clustering» бесплатно?
Да, книга доступна для скачивания в формате fb2 без регистрации и без оплаты на сайте Книгизм. Файл сохраняет структуру глав, иллюстрации и метаданные — подходит для FBReader, Cool Reader, AlReader и других читалок на смартфоне или электронной книге.
Можно ли читать книгу «Clustering» онлайн без скачивания?
Да, полная версия произведения автора Xu Rui доступна для онлайн-чтения прямо в браузере. Откройте страницу книги, нажмите кнопку «Читать» — текст загрузится с пагинацией, настройкой шрифта, темой оформления и закладкой текущей позиции.
К какому жанру относится «Clustering»?
Книга относится к жанру «Математика».
📲 Как читать книгу на Книгизм
Книга «Clustering» автора Xu Rui доступна на Книгизм бесплатно. Вы можете скачать файл fb2 для дальнейшего чтения в любой читалке (FBReader, Cool Reader, AlReader и других) на смартфоне, планшете или электронной книге. Формат fb2 сохраняет структуру глав, иллюстрации, оглавление и метаданные. Альтернатива — онлайн-чтение полной версии в браузере сразу без скачивания и без регистрации.